
16 lutego Alibaba wypuściła Qwen 3.5 — otwarty model AI (licencja Apache 2.0, pełna swoboda komercyjna), który w benchmarkach staje na równi z GPT-5.2, Claude Opus 4.5 i Gemini 3 Pro. W kilku kategoriach tj. rozumienie dokumentów, zadania agentowe wysuwa się nawet na prowadzenie. I co istotne: da się go uruchomić na sprzęcie stojącym w biurze.
Poniżej rozkładamy ten model na części: architektura, benchmarki w porównaniu z konkurencją (płatną i open-source), a na koniec konkretne kalkulacje sprzętowe — od minikomputera za 34 tys. PLN po klaster produkcyjny.
Dlaczego Qwen 3.5 da się uruchomić lokalnie?
Kluczem jest architektura Mixture-of-Experts (MoE). W tradycyjnym wydaniu model LLM działa jak jeden duży mózg — przy każdym zapytaniu aktywuje wszystkie swoje parametry. MoE podchodzi do tego inaczej: model składa się z wielu wyspecjalizowanych bloków (ekspertów), ale przy każdym tokenie aktywowana jest tylko ich niewielka część. Reszta czeka.
W przypadku Qwen 3.5 wygląda to tak: 397 mld parametrów łącznie (tyle model „wie"), ale tylko 17 mld aktywnych na token — z 512 ekspertów router wybiera 11 najbardziej odpowiednich. Okno kontekstowe wynosi 262 144 tokeny (~500 stron A4), z możliwością rozszerzenia do ponad miliona przez YaRN RoPE. Poza tekstem model przetwarza obrazy (do 1344 × 1344 px) i wideo (do 60 s). Obsługuje 201 języków, w tym polski.
Praktyczna konsekwencja: model, który aktywuje 17B parametrów na token, potrzebuje podczas inferencji tyle pamięci operacyjnej, co model dense o zbliżonej wielkości — a nie tyle, ile sugeruje łączna liczba 397B. Dlatego da się go zmieścić na sprzęcie, który normalnie obsłużyłby model 20–30B.
Benchmarki: Qwen 3.5 vs. modele zamknięte
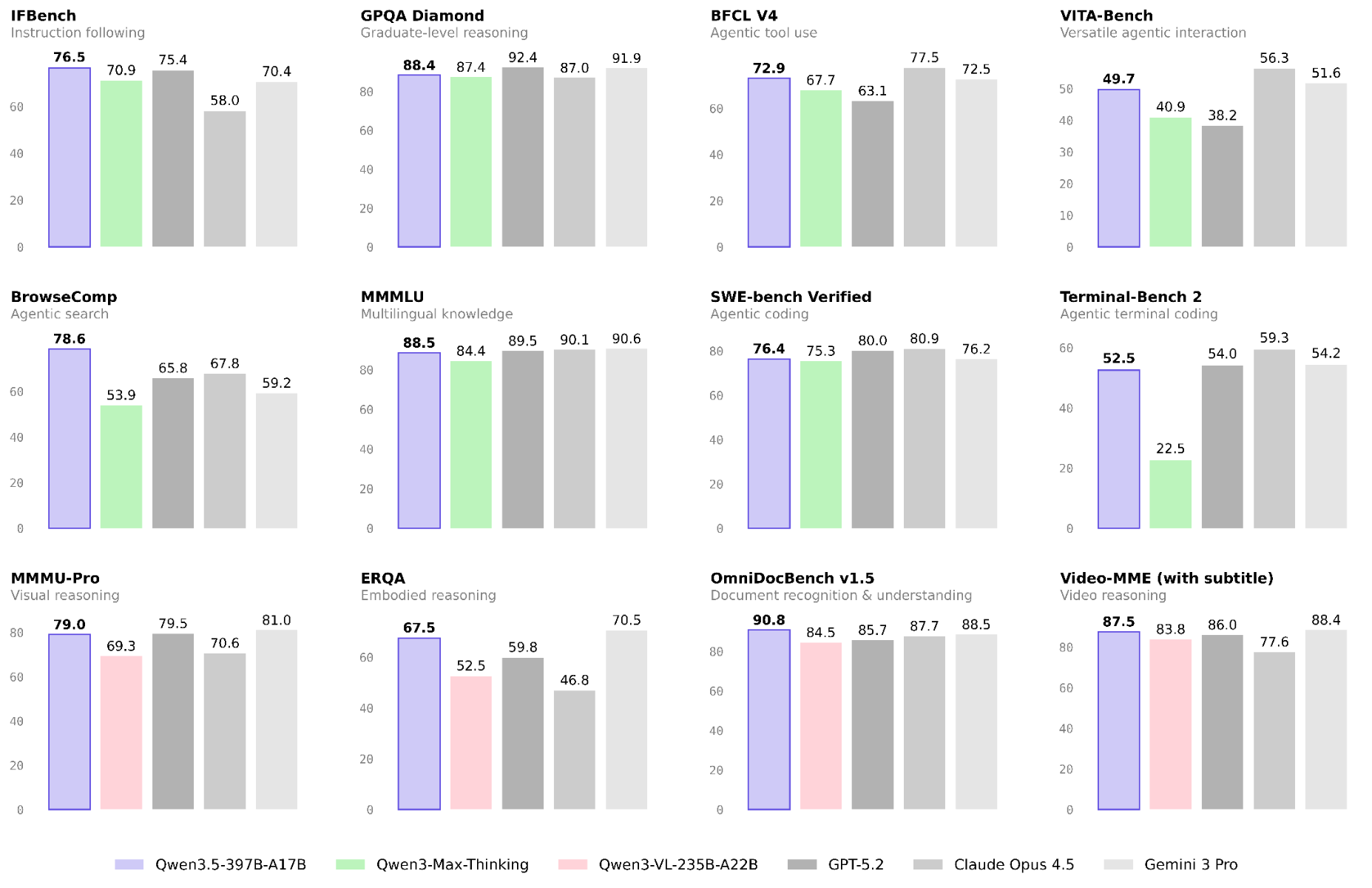
Źródło: qwen.ai
Rozumowanie i matematyka
AIME to zadania z olimpiad matematycznych, GPQA Diamond — pytania na poziomie doktoratu z nauk ścisłych.
| Test | Qwen 3.5 | GPT-5.2 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|
| AIME26 | 91.3 | 96.7 | 93.3 | 90.6 |
| GPQA Diamond | 88.4 | 92.4 | 87.0 | 91.9 |
| MMLU-Pro | 87.8 | 87.4 | 89.5 | 89.8 |
GPT-5.2 prowadzi w matematyce i nauce ścisłej, ale Qwen (91.3 AIME26) jest powyżej Gemini i blisko Claude. W wiedzy ogólnej (MMLU-Pro) Claude i Gemini mają lekką przewagę nad Qwenem — dystans rzędu 2 punktów.
Kodowanie
SWE-bench Verified polega na tym, że model dostaje prawdziwy bug report z GitHuba i musi samodzielnie zlokalizować problem i naprawić kod.
| Test | Qwen 3.5 | GPT-5.2 | Claude Opus 4.6 | Gemini 3 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 76.4 | 80.0 | 80.9 | 76.2 |
| LiveCodeBench v6 | 83.6 | 87.7 | 84.8 | 90.7 |
| Terminal-Bench 2.0 | 52.5 | 54.0 | 59.3 | 54.2 |
Obraz jest niejednoznaczny: Claude prowadzi w naprawianiu prawdziwych bugów (SWE-bench 80.9%), Gemini wiedzie na LiveCodeBench (90.7%), Claude też wygrywa Terminal-Bench (59.3%). Qwen w każdym z tych testów mieści się blisko GPT-5.2 i Gemini. Jak na model open-source — wynik ponadprzeciętny.
Zadania agentowe
Agent AI to model, który nie tylko odpowiada na pytania, ale potrafi samodzielnie realizować wielokrokowe zadania — przeszukiwać internet, korzystać z narzędzi, wykonywać złożone instrukcje. BrowseComp mierzy umiejętność przeszukiwania sieci, IFBench — precyzję wykonywania instrukcji.
| Test | Qwen 3.5 | GPT-5.2 | Claude Opus 4.6 | Gemini 3 Pro |
|---|---|---|---|---|
| BrowseComp | 78.6 | 65.8 | 67.8 | 59.2 |
| IFBench | 76.5 | 75.4 | 58.0 | 70.4 |
| Tau2-Bench | 86.7 | 87.1 | 91.6 | 85.4 |
| MCPMark | 46.1 | 57.5 | 42.3 | 53.9 |
W przeszukiwaniu sieci (BrowseComp) Qwen prowadzi — 78.6 wobec 67.8 Claude i 65.8 GPT-5.2. Gemini zostaje daleko z tyłu (59.2). W wykonywaniu instrukcji (IFBench) Qwen też jest na czele. Słabszym punktem jest MCPMark — tutaj GPT-5.2 (57.5) i Gemini (53.9) mają wyraźną przewagę nad Qwenem (46.1). Jeśli planujesz budować agentów AI przeszukujących sieć lub działających na precyzyjnych instrukcjach — to mocny kandydat.
Rozumienie dokumentów
OmniDocBench testuje, jak model radzi sobie z dokumentami biznesowymi: fakturami, tabelami, diagramami, skanami.
| Test | Qwen 3.5 | GPT-5.2 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|
| OmniDocBench v1.5 | 90.8 | 85.7 | 87.7 | 88.5 |
| MMMU-Pro | 79.0 | — | — | 81.0 |
| MMMLU | 88.5 | 89.5 | 90.1 | 90.6 |
90.8% na OmniDocBench to najwyższy wynik spośród wszystkich testowanych modeli — Qwen czyta dokumenty biznesowe lepiej niż GPT-5.2, Claude i Gemini. W wiedzy wielojęzycznej (MMMLU) jest nieznacznie za Gemini (90.6) i Claude (90.1), co nie zmienia faktu, że obsługuje 201 języków natywnie. Dla firm przetwarzających dokumentację techniczną, normy ISO, raporty z inspekcji — OmniDocBench to metryka, która liczy się najbardziej.
Benchmarki: Qwen 3.5 vs. inne modele open-source
| Cecha | Qwen 3.5 | Llama 4 Maverick (Meta) | DeepSeek V3.2 |
|---|---|---|---|
| Licencja | Apache 2.0 | Llama Community (ograniczenia) | DeepSeek License (ograniczenia) |
| Aktywne parametry | 17B | 17B | 37B |
| Okno kontekstowe | 262K → 1M+ | 10M | 128K |
| Multimodalność | Tekst + obraz + wideo | Tekst + obraz | Tylko tekst |
| OmniDocBench v1.5 | 90.8 | — | — |
| Języki | 201 | ~100 | ~50 |
Llama 4 Maverick ma gigantyczne okno kontekstowe (10M tokenów) — przydatne przy analizie bardzo długich dokumentów. DeepSeek V3.2 aktywuje 37B parametrów, więc w niektórych zadaniach jest dokładniejszy, ale wymaga 2× więcej pamięci. Qwen 3.5 prowadzi w multimodalności (obsługuje też wideo), rozumieniu dokumentów i liczbie języków.
Ile pamięci potrzeba?
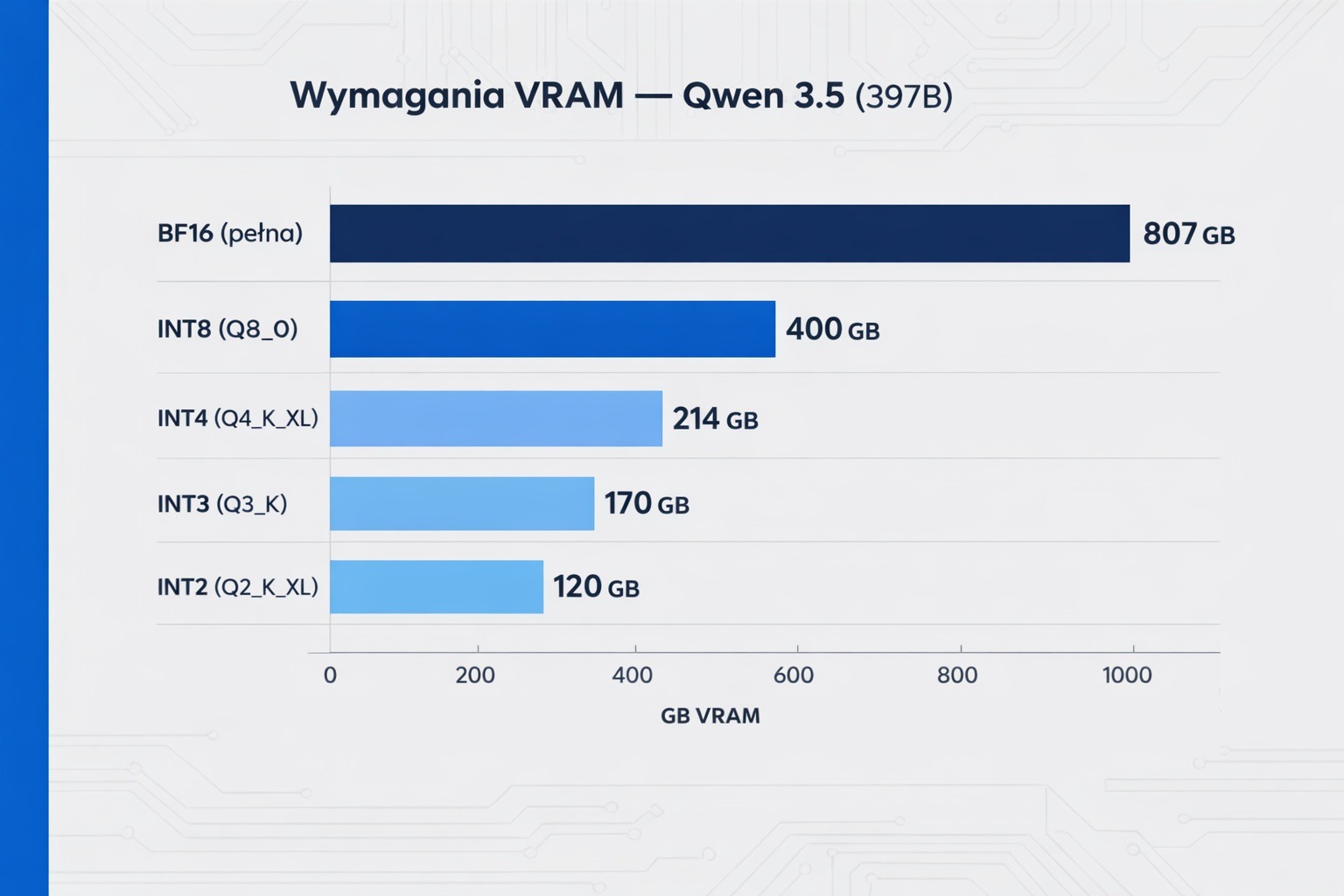
Model AI to zbiór miliardów liczbowych wag. Kwantyzacja polega na zmniejszeniu precyzji tych wag — np. z 16-bitowych na 4-bitowe. Rozmiar modelu spada kilkukrotnie, a jakość odpowiedzi obniża się nieznacznie. To trochę jak różnica między zdjęciem RAW a JPEG — mniejszy plik, minimalnie mniej detali.
| Precyzja | Rozmiar | Wymagana pamięć | Szybkość (~tok/s) |
|---|---|---|---|
| BF16 (pełna) | ~807 GB | 8× H100 (640 GB) | ~45 |
| INT8 | ~400 GB | ~512 GB | ~20 |
| INT4 | ~214 GB | ~256 GB | ~25 |
| INT3 | ~170 GB | ~192 GB | ~15 |
| INT2 | ~120 GB | ~128 GB | ~8 |
Jeden token to mniej więcej ¾ słowa. 25 tok/s oznacza komfortową konwersację — odpowiedź w kilka sekund.
Offloading ekspertów MoE
Ponieważ w danym momencie pracuje tylko 11 z 512 ekspertów, w llama.cpp można nieaktywnych przenieść do zwykłego RAM-u, a na GPU zostawić tylko warstwy uwagi i routing. Dzięki temu model 397B ruszy nawet na jednej karcie GPU z 24 GB — generowanie będzie wolniejsze (~5–10 tok/s), ale dla wielu zastosowań (analiza dokumentów, RAG) to wystarczy.
KV-cache
Przy przetwarzaniu długich tekstów model musi przechowywać w pamięci kontekst tego, co już przeczytał — to tzw. KV-cache. Przy 262K tokenów potrafi zająć kilkadziesiąt GB. Kompresja KV-cache w llama.cpp (kwantyzacja kluczy i wartości) redukuje to o 50–70% bez zauważalnego wpływu na jakość.

Scenariusz 1: Stacja deweloperska - 2× EdgeXpert (DGX Spark)

Dla kogo: zespół R&D (2–3 osoby), prototypowanie, testy koncepcji.
EdgeXpert to miniaturowy komputer AI — 15 × 15 × 5 cm, 1.2 kg. W środku NVIDIA GB10 Grace Blackwell Superchip: procesor ARM + GPU na jednym chipie, połączone przez NVLink. 128 GB zunifikowanej pamięci LPDDR5x (CPU i GPU korzystają z tej samej puli). Wydajność: 1 000 TOPS w FP4. Cena: od ok. 3 000 do 4 000 USD za sztukę.
Dwa EdgeXperty połączone przez ConnectX dają 256 GB pamięci i 2 000 TOPS. Qwen 3.5 w INT4 (214 GB) mieści się z marginesem na KV-cache (kontekst do ~16K tokenów). Prędkość generowania: ~15–25 tok/s.
Koszt: ok. 30 798 zł netto za parę. Oprogramowanie (Ollama, vLLM) darmowe. Pobór mocy: ~120 W na sztukę. Żadnych opłat za API ani abonamentu.
Scenariusz 2: Stacja AI - XpertStation WS300 (DGX Station)

Dla kogo: firma, która oprócz inferencji chce fine-tunować modele, uruchamiać pipeline'y multimodalne (tekst + obraz) i kilku agentów jednocześnie.
To desktopowa stacja na architekturze NVIDIA DGX Station — 72-rdzeniowy procesor ARM Grace + GPU Blackwell Ultra + 775 GB pamięci koherentnej (279 GB HBM3e na GPU + 496 GB LPDDR5X). Łączność: do 800 Gb/s (ConnectX-8 SuperNIC).
Na WS300 zmieści się Qwen 3.5 w INT8 (400 GB) z pełnym kontekstem 262K tokenów i szybkością ~40–60 tok/s. Możliwy jest fine-tuning przez LoRA na modelach do 200B, system multiagentowy (2–3 agenty równolegle) oraz pipeline wizyjny: kamera → analiza obrazu → raport → sprawdzenie z dokumentacją.
Scenariusz 3: Klaster produkcyjny - MGX z GPU H200 NVL

Dla kogo: firma, która wdraża AI produkcyjnie — system RAG dla dziesiątek/setek użytkowników, wieloagentowe pipeline'y, przetwarzanie dokumentacji na skalę organizacji.
Wariant A: MSI CG290-S3063 (2U) — serwer inferencyjny
Rackmount 2U, Intel Xeon 6, do 4 kart NVIDIA H200 NVL (564 GB HBM3e) lub 4× RTX PRO 6000 (384 GB GDDR7).
Qwen 3.5 INT4 na 4× H200 obsłuży 20–40 równoległych zapytań z prędkością ~80–120 tok/s. Wystarczy na firmowy RAG dla całego działu. RTX PRO 6000 jest tańsza i świetnie sprawdza się w inferencji; H200 lepiej się nadaje, jeśli planujesz też szkolenie modeli.
Wariant B: MSI CG480-S5063 (4U) — trening i hub agentowy
Serwer 4U, 2× Intel Xeon 6, do 8 kart H200 NVL (1 128 GB VRAM) lub 8× RTX PRO 6000 (768 GB). Do 8 TB RAM DDR5.
Na CG480 z 8× H200 zmieści się Qwen 3.5 w pełnej precyzji BF16 (807 GB) z ponad 300 GB zapasu na KV-cache. Alternatywnie: kilka modeli równolegle — agent główny (Qwen 3.5 Q4) + agenty specjalistyczne (Qwen 3 32B) + embedding + reranker. Fine-tuning LoRA na pełnym modelu 397B też jest realny.
Skalowanie korporacyjne
Oferujemy rozwiązanie rackowe: do 32 serwerów (256 kart GPU) połączonych przez NVIDIA Spectrum-X. Setki agentów, tysiące zapytań na minutę.
Podsumowanie
| Zastosowanie | Sprzęt | Pamięć | Użytkownicy | Szac. koszt |
|---|---|---|---|---|
| Prototyp / R&D | 2× MSI EdgeXpert | 256 GB | 1–2 | Sprawdź cenę |
| Rozwój + fine-tuning | MSI XpertStation WS300 | 775 GB | 3–5 | Na zapytanie |
| Produkcja: inferencja | MSI CG290 + 4× H200 | 564 GB | 20–40 | Na zapytanie |
| Produkcja: multi-agent | MSI CG480 + 8× H200 | 1 128 GB | 50–100+ | Na zapytanie |
Jak zacząć? Quick Guide:
Krok 1: Pobierz model w formacie GGUF z Hugging Face (polecam wersje od Unsloth — lepsza kwantyzacja). Dobierz precyzję do swojego sprzętu, np. Q4_K_XL przy ~256 GB pamięci.
Krok 2: Zainstaluj framework. Najprostszy start: ollama run qwen3.5. Do produkcji: vLLM (batching wielu użytkowników) lub SGLang (najszybszy backend dla MoE).
Krok 3: Skonfiguruj offloading ekspertów: -ot ".ffn_.*_exps.=CPU" w llama.cpp przenosi nieaktywnych ekspertów do RAM-u, zmniejszając wymagania GPU.
Krok 4: Włącz kompresję KV-cache dla długich kontekstów: --cache-type-k q8_0 --cache-type-v q4_0 --flash-attn.
Krok 5: Zmierz wydajność pod obciążeniem — tok/s, czas do pierwszego tokena, zużycie pamięci przy wielu równoczesnych zapytaniach.
Wnioski
Qwen 3.5 przesuwa granicę tego, co można uruchomić lokalnie. Model dorównujący GPT-5.2 i Claude Opus 4.5, dostępny za darmo pod Apache 2.0, który dzięki architekturze MoE mieści się na sprzęcie kosztującym ułamek serwerowni.
Obsługuje 201 języków (w tym polski), ma natywną multimodalność, a w rozumieniu dokumentów biznesowych (OmniDocBench 90.8%) bije całą konkurencję. Dla firm przetwarzających dokumentację techniczną, normy branżowe czy raporty z inspekcji — to realna przewaga.
Mniejsze warianty (7B, 14B, 32B) nie wyszły jeszcze, ale Alibaba je zapowiedziała. Kiedy się pojawią, model 14B w INT4 ruszy na jednej karcie RTX 4090 za ok. 8 000 PLN. Na dziś: dwa EdgeXperty za 34 tysiące złotych to minimalna, ale działająca konfiguracja. Bez chmury, bez abonamentu, dane zostają w firmie.
Potrzebujesz pomocy w doborze platformy sprzętowej do lokalnego AI? Skontaktuj się z zespołem elmatic.net — pomagamy firmom z sektora przemysłowego budować systemy AI lokalnie.




















