
Od pikseli do kontekstu
Klasyczna inspekcja wizyjna opiera się na sieciach konwolucyjnych (CNN) wyuczonych na zbiorach zdjęć z etykietami: OK, NOK, typ defektu A, typ defektu B. System działa dobrze dopóki defekty mieszczą się w kategoriach, które ktoś wcześniej zdefiniował i na których model trenowano. Problem pojawia się, gdy na linii wydarzy się coś nowego - nietypowe zarysowanie, zmiana odcienia materiału po modyfikacji dostawcy, deformacja, której nikt wcześniej nie widział.
VLM - Vision Language Model - to architektura łącząca przetwarzanie obrazu z modelem językowym. Zamiast klasyfikować zdjęcie do jednej z N kategorii, model analizuje obraz i generuje odpowiedź tekstową. Różnica w praktyce wygląda tak:
CNN powie: „NOK - klasa: zarysowanie, pewność: 94%".
VLM powie: „Widoczne podłużne zarysowanie o długości ok. 12 mm na powierzchni roboczej, równoległe do kierunku podawania materiału. Charakter uszkodzenia sugeruje kontakt z elementem prowadzącym - sprawdź stan rolek dociskowych na stacji 3, porównaj z incydentem z 14 stycznia."
To nie jest science fiction. Modele takie jak Qwen2.5-VL-72B czy LLaVA-NeXT już to potrafią. Pytanie brzmi: na czym to uruchomić na hali produkcyjnej.
2070 TFLOPS na brzegu sieci
NVIDIA Jetson Thor zmienił w tym roku układ sił w edge AI. Moduł dostarcza 2070 TFLOPS w trybie FP4 przy poborze mocy 40-130 W (konfigurowalnym), ze 128 GB zunifikowanej pamięci. To 7,5-krotny wzrost wydajności AI w porównaniu z Jetson AGX Orin, przy 3,5-krotnie lepszej efektywności energetycznej.
Advantech już oferuje systemy przemysłowe z Jetson Thor - gotowe platformy z certyfikatami, rozszerzonym zakresem temperatur i interfejsami do kamer przemysłowych (GigE Vision, USB3 Vision). Z perspektywy wdrożenia to kluczowe, bo sam moduł obliczeniowy to dopiero połowa sukcesu. Potrzebujesz obudowy IP-rated, zasilania 24 VDC, portów PoE do kamer i systemu chłodzenia, który nie padnie po roku pracy w hali lakierniczej.
128 GB pamięci zunifikowanej pozwala załadować model VLM klasy 70B w kwantyzacji Q4 (~35-40 GB wag) i jednocześnie przetwarzać strumień wideo z kilku kamer w rozdzielczości 4K. Wcześniej wymagało to dedykowanego serwera z kartą A100. Dzisiaj mieści się w urządzeniu brzegowym na szynie DIN.
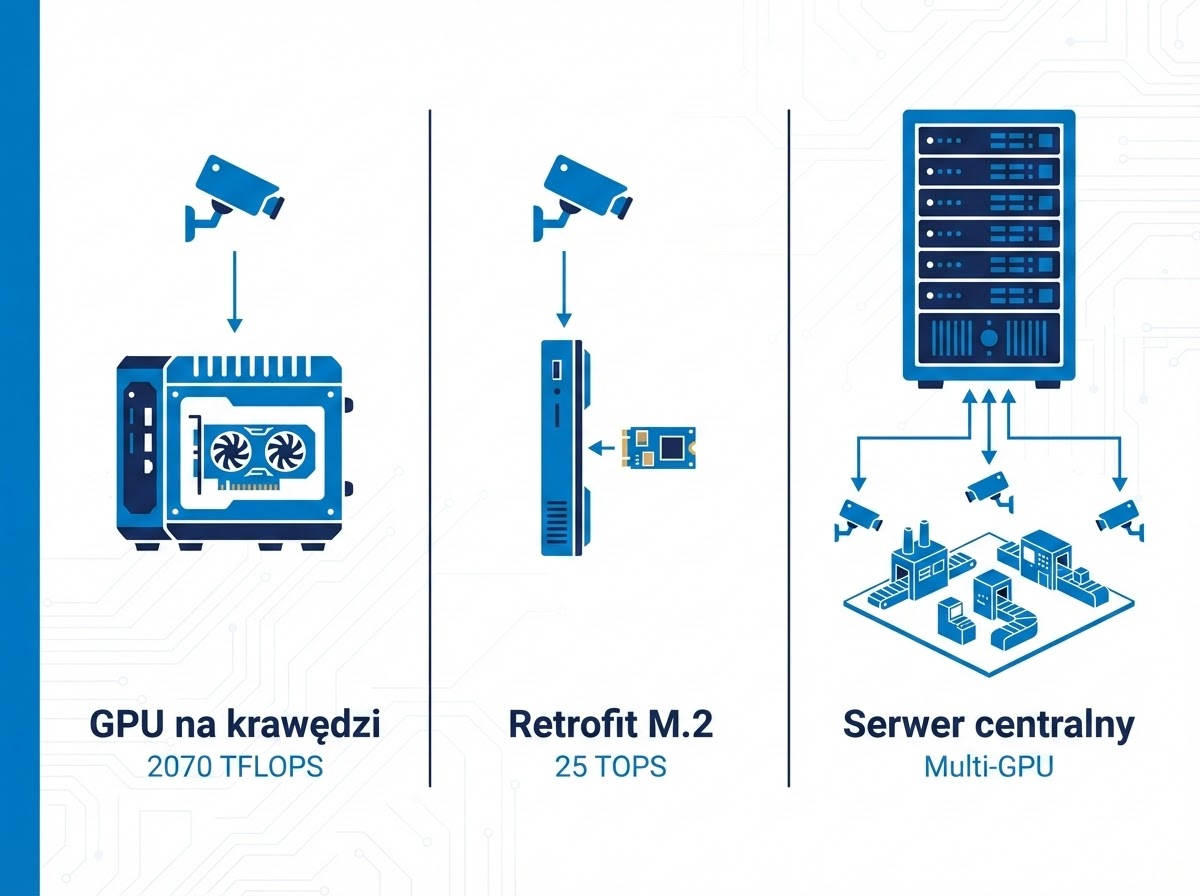
Trzy scenariusze wdrożenia
Nie każda linia potrzebuje 2070 TFLOPS. Nie każdy budżet na to pozwala. Dlatego warto spojrzeć na VLM z perspektywy trzech różnych architektur — każda ma sens w innych warunkach.
Pełna inspekcja VLM przy linii
Platforma Advantech z Jetson Thor lub ETA 10108GC z kartą NVIDIA RTX - obydwa warianty zapewniają wystarczającą moc do uruchomienia dużego VLM (Qwen2.5-VL-72B, InternVL2-76B) bezpośrednio przy stanowisku inspekcji. Model analizuje każdy produkt w czasie rzeczywistym, generując nie tylko werdykt OK/NOK, ale pełny raport z opisem defektu, prawdopodobną przyczyną i rekomendacją działania.
ETA 10108GC (oparty o Nuvo-10108GC) daje tu pewną elastyczność - architektura x86 z dedykowanym GPU pozwala uruchomić obok VLM-a dodatkowe oprogramowanie: system SCADA, bazę danych defektów, dashboard operatorski. Z naszego doświadczenia wynika, że integratorzy często potrzebują tego „ekosystemu" wokół samego modelu AI.
Latencja w tym scenariuszu to 200-500 ms na analizę jednego zdjęcia przy rozdzielczości 4K - wystarczająco szybko dla większości procesów pakowania, montażu i kontroli końcowej.
Retrofit istniejącego systemu wizyjnego
Nie każdy zakład jest gotowy na wymianę całej infrastruktury. Advantech EAI-1961 z akceleratorem DEEPX DX-M1 to moduł M.2 dostarczający 25 TOPS w formacie karty rozszerzeń. Wsadzasz go do istniejącego komputera przemysłowego i zyskujesz możliwość uruchomienia mniejszego VLM - na przykład Qwen2.5-VL-7B albo PaliGemma 2.
Oczywiście 25 TOPS to nie 2070 TFLOPS. Model 7B nie napisze Ci rozprawki o przyczynach defektu. Ale potrafi coś, czego CNN nie potrafi: odpowiedzieć na pytanie operatora w naturalnym języku. „Co widzisz na tym zdjęciu?" - i dostaje zwięzłą odpowiedź zamiast kodu błędu.
Koszt wejścia jest minimalny - moduł M.2, aktualizacja softu, ewentualnie dodanie kamery o wyższej rozdzielczości. Dla zakładów, które chcą przetestować VLM bez dużej inwestycji, to rozsądna ścieżka.
Centralny serwer AI dla wielu linii
Trzecia opcja to architektura hub-and-spoke: kamery przy każdej linii, a przetwarzanie w jednym serwerze GPU w serwerowni zakładu. W tej kategorii oferujemy serwery GPU klasy enterprise z obsługą wielu kart NVIDIA - wystarczająco wydajne, żeby obsłużyć 10-20 linii produkcyjnych jednocześnie jednym modelem VLM.
Ma to sens, gdy zakład ma stabilną sieć LAN o niskiej latencji (poniżej 5 ms między halą a serwerownią), centralne IT do zarządzania infrastrukturą i potrzebę jednego modelu trenowanego na danych ze wszystkich linii. Wadą jest zależność od sieci - jeśli switch padnie, wszystkie linie tracą inspekcję. W architekturze edge każda linia działa niezależnie.

Hybrydowa przyszłość inspekcji
Branżowy trend, który obserwujemy, to podejście hybrydowe: klasyczny system wizyjny (szybki CNN, deterministyczny, MTBF powyżej 50 000 godzin) zajmuje się pomiarami geometrycznymi i prostą klasyfikacją binarną. VLM wchodzi jako druga warstwa - analizuje przypadki odrzucone przez CNN, generuje raporty z kontekstem, odpowiada na pytania inżynierów utrzymania ruchu.
Gartner prognozuje, że do 2027 roku organizacje będą 3-krotnie częściej korzystać z mniejszych, wyspecjalizowanych modeli AI niż z dużych modeli ogólnego przeznaczenia. W kontekście inspekcji wizualnej to oznacza właśnie takie podejście: szybki, lekki model do detekcji + VLM do analizy i raportowania.
Rynek edge AI rośnie w tempie 21,7% rocznie i ma osiągnąć 118 miliardów dolarów do 2033 roku. Producenci sprzętu reagują - Advantech z Jetson Thor, Neousys z platformami GPU, MSI EPS z serwerami enterprise. Infrastruktura jest gotowa. Modele VLM dojrzewają z każdym kwartałem. Moim zdaniem jesteśmy w punkcie, w którym wdrożenie VLM na produkcji przestaje być projektem R&D, a staje się decyzją inżynieryjną.
Jeśli rozważsz taki krok, dobierzemy platformę do Twoich wymagań - od pojedynczego stanowiska kontroli po system obejmujący cały zakład.






















