
Komputer Box PC do zastosowań AI, Intel Core i3/i5/i7/i9 12/13/14 gen., do 128GB RAM, możliwość montażu karty graficznej NVIDIA do 350W
Przy złożeniu zamówienia do godziny 15:00 paczka zostanie wysłana jeszcze tego samego dnia Dostępny

Jaka karta graficzna do aplikacji deep learning sprawdzi się najlepiej? Odruchowo powiemy: taka, którą charakteryzuje wyjątkowa wydajność. Niestety, to nie takie proste. Karty graficzne NVIDIA GEFORCE GTX i AMD o zaawansowanej architekturze cechuje wiele parametrów (DLSS, ilość rdzeni CUDA, itd.). Deep Learning czy też Machine Learning to z kolei nie tylko zaawansowane technologie, ale także wymagania dotyczące niezawodności w bardzo specyficznych aplikacjach.
W artykule przyjrzymy się temu zagadnieniu. Nie będziemy analizować poszczególnych modeli kart graficznych, a skupimy się na różnych konfiguracjach komputerów przemysłowych opartych na jednej z najlepszych kart graficznych na rynku - NVDII 4080.
Dziedzina Deep Learning’u odnotowała w ostatnich latach znaczny wzrost, rewolucjonizując różne branże dzięki swoim zastosowaniom w sztucznej inteligencji, rozpoznawaniu obrazu, mowy i nie tylko. Jednym z kluczowych czynników wpływających na sukces projektów głębokiego uczenia jest wybór odpowiedniego układu GPU (Graphics Processing Unit). Wybór odpowiedniej karty graficznej dla aplikacji Deep Learning ma kluczowe znaczenie dla osiągnięcia optymalnej wydajności i efektywności. W niniejszym przewodniku przeanalizujemy kluczowe czynniki, które należy wziąć pod uwagę przy wyborze układu GPU do zadań głębokiego uczenia.
W dziedzinie głębokiego uczenia, każda funkcja odgrywa kluczową rolę w określaniu ogólnej wydajności i efektywności GPU. W tej części artykułu przedstawię podstawowe parametry, które w szczególności należy wziąć pod uwagę przy doborze karty graficznej do naszej aplikacji DL, na podstawie specyfikacji karty graficznej NVIDIA RTX 4080.
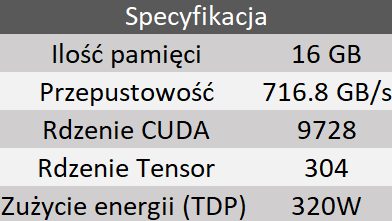
Odpowiada za obsługę danych związanych z procesami uczenia i wnioskowania. Pamięć karty graficznej, nazywana także jako VRAM, ma duży wpływ na płynność oraz wydajność w programach graficznych. Przechowuje ona dane o obrabianym aktualnie obrazie, np. teksturach. Im większa pojemność, tym więcej detali w lepszej jakości można wyświetlić na ekranie.
Jest niezbędna do szybkiego transferu danych pomiędzy procesorem graficznym i pamięcią VRAM.
Chodzi o rdzenie przetwarzania graficznego (GPU), które są używane do przyspieszania obliczeń związanych z grafiką, a także do ogólnego przetwarzania równoległego bezpośrednio przyczyniając się do szybkości i wydajności algorytmów głębokiego uczenia.
Zaprojektowane specjalnie do operacji macierzowych powszechnych w głębokim uczeniu, przyspieszają obliczenia, zwiększając ogólną moc obliczeniową dla zadań takich jak szkolenie sieci neuronowych.
Ma kluczowe znaczenie, szczególnie w środowiskach świadomych energetycznie, ponieważ bezpośrednio wpływa na koszty operacyjne i ślad środowiskowy uruchamiania obciążeń Deep Learning’u, co sprawia, że konieczne jest znalezienie równowagi między mocą obliczeniową a efektywnością energetyczną.
Zacznę od wytłumaczenia co kryje się pod tymi pojęciami. INT8 (8-bitowa liczba całkowita), FP16 (16-bitowa liczba zmiennoprzecinkowa) i FP32 (32-bitowa liczba zmiennoprzecinkowa) to różne formaty liczbowe używane w modelach Deep Learning’u. Formaty te reprezentują precyzję, z jaką wartości liczbowe są przechowywane i manipulowane podczas treningu i wnioskowania w modelach DL. Wybór precyzji może znacząco wpływać na wymagania obliczeniowe i wydajność modelu uczenia głębokiego.
W przypadku tego formatu mamy do czynienia z precyzją 8 bitów. Często jest on używany podczas wnioskowania w modelach Deep Learning, zwłaszcza w scenariuszach, gdzie przepustowość pamięci i przechowywanie danych są kluczowe. Pozwala na znaczne skompresowanie wag modelu i aktywacji, zmniejszając zapotrzebowanie na pamięć. Niestety mniejsza precyzja może prowadzić do utraty dokładności.
Precyzja w tym przypadku wynosi 16 bitów. FP16 jest ostatnio używany głównie w aplikacjach DL, ponieważ zajmuje połowę pamięci i teoretycznie mniej czasu w obliczeniach niż FP32. Wiąże się to ze znaczną utratą zakresu, który obejmuje FP16, a także precyzji, którą może faktycznie utrzymać. Format ten jest najczęściej używany w aplikacjach Deep Learningu, gdzie wymagany zakres liczb jest stosunkowo niewielki, a także nie ma zapotrzebowania na precyzję.
Dla FP32 precyzja wynosi 32 bity. Powszechnie FP32 używane jest podczas treningu modeli DL / AI, gdzie wysoka precyzja jest istotna dla utrzymania dokładnych aktualizacji wag podczas optymalizacji. FP32 wymaga większej ilości pamięci i zasobów obliczeniowych w porównaniu do formatów o mniejszej precyzji. Choć jest istotne podczas treningu, używanie FP32 podczas wnioskowania może być kosztowne obliczeniowo.
Na poniższej grafice możemy zauważyć przykłady zastosowań i możliwości wymienionych wyżej formatów:

W tej części artykułu zajmiemy się najważniejszą, z punktu widzenia kupującego, rzeczą czyli odpowiemy sobie na pytanie w jaki sposób wybrać odpowiednią kartę graficzną, na co powinniśmy zwrócić uwagę? Podczas wybierania odpowiedniego GPU dla naszych aplikacji głębokiego uczenia powinniśmy rozważyć wpływ kilku czynników na efektywność i wydajność.
Podczas doboru kart graficznych do zastosowań w Deep Learningu, kluczowym aspektem, który wymaga uwagi, są zarówno koszty, jak i niezawodność. Wybór odpowiedniej karty graficznej może znacząco wpłynąć na efektywność naszego projektu. Z punktu widzenia kosztów, inwestycje w nowoczesne karty graficzne z dedykowanymi jednostkami obliczeniowymi AI, takimi jak tensorowe jednostki przetwarzania grafiki (TPU), mogą generować znaczne korzyści pod względem przyspieszenia obliczeń. Jednak warto również rozważyć, czy możliwości karty są w pełni wykorzystywane w kontekście konkretnego projektu, aby uniknąć nadmiernych kosztów.
Niezawodność jest równie istotnym kryterium, zwłaszcza w przypadku projektów, które wymagają ciągłej i stabilnej pracy. Wysoka niezawodność zapewnia ciągłe przetwarzanie danych, co jest kluczowe w przypadku modeli Deep Learning, które wymagają długich okresów trenowania. Należy uwzględnić nie tylko wydajność karty graficznej, ale także jej zdolność do utrzymania stabilnej temperatury pracy, co wpływa na długoterminową niezawodność sprzętu. Przemyślane podejście do doboru kart graficznych, uwzględniające zarówno koszty, jak i niezawodność, pozwoli efektywnie zrównoważyć inwestycje i osiągnąć optymalne rezultaty w projektach Deep Learning.
Jeżeli niezawodność i trwałość są dla nas najważniejsze, powinniśmy zdecyować się na zakup przemysłowych kart graficznych. W przypadku, gdy opłacalność ma kluczowe znaczenie powinniśmy wybrać komercyjne karty graficzne. Poniżej przedstawiamy przykłady GPU z klasy przemysłowej i komercyjnej.

Wydajność energetyczna w kontekście przetwarzania danych w jednostkach obliczeniowych, zwłaszcza w aplikacjach związanych z sztuczną inteligencją, jest istotnym kryterium oceny efektywności systemów. Jednym z mierników tej efektywności jest wskaźnik TOPS/W. Odnosi się on do liczby tera operacji na sekundę, które jednostka obliczeniowa (na przykład procesor czy karta graficzna) jest w stanie wykonać przy jednoczesnym zużyciu jednego watu mocy elektrycznej.
Im wyższy wskaźnik TOPS/W, tym bardziej efektywna jest jednostka obliczeniowa w przetwarzaniu danych przy minimalnym zużyciu energii. Optymalna wydajność energetyczna ma kluczowe znaczenie w dziedzinach, gdzie moc obliczeniowa i zużycie energii są ograniczone, takie jak urządzenia mobilne, pojazdy autonomiczne czy systemy wbudowane.
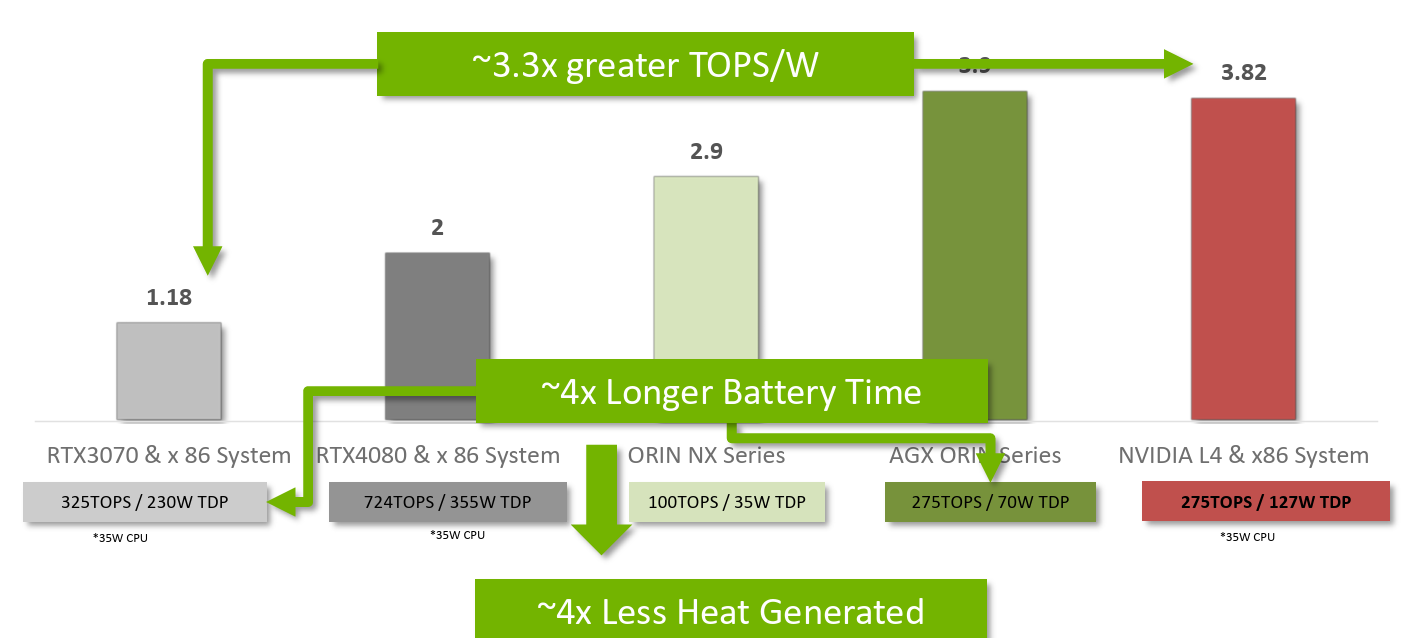
W praktyce, osiągnięcie wysokiej wydajności energetycznej może wymagać zaawansowanych architektur układów scalonych, zoptymalizowanych dla konkretnych zastosowań, takich jak przetwarzanie macierzy w algorytmach głębokiego uczenia się. Przy wyborze jednostki obliczeniowej do zastosowań związanych z sztuczną inteligencją, analiza wskaźnika TOPS/W stanowi ważny aspekt, umożliwiający efektywne wykorzystanie zasobów obliczeniowych przy minimalnym zużyciu energii.

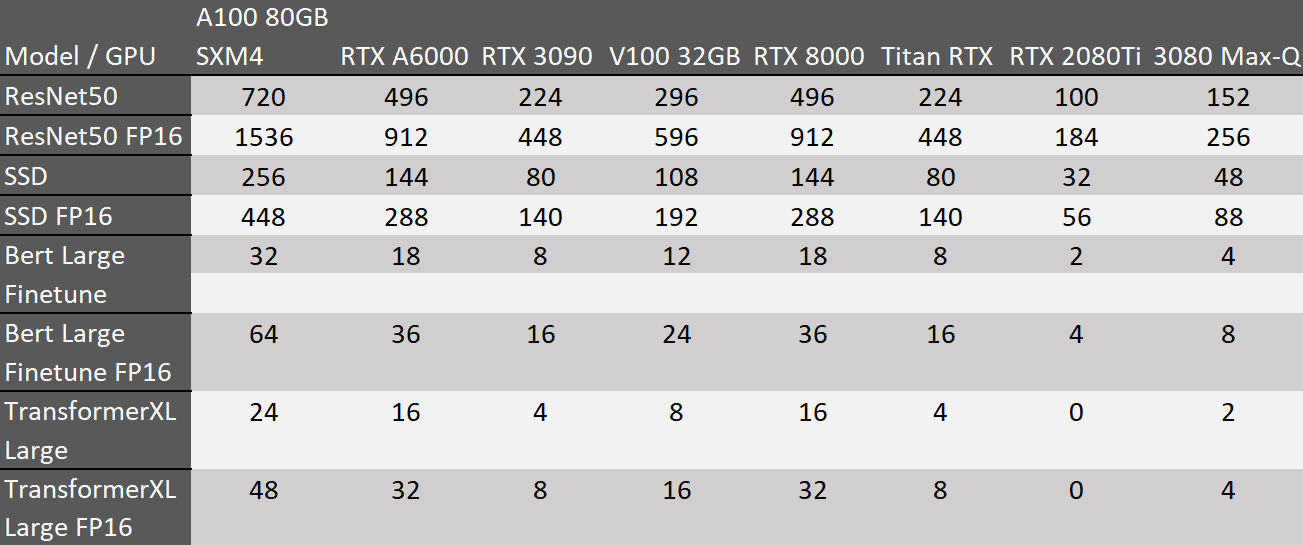
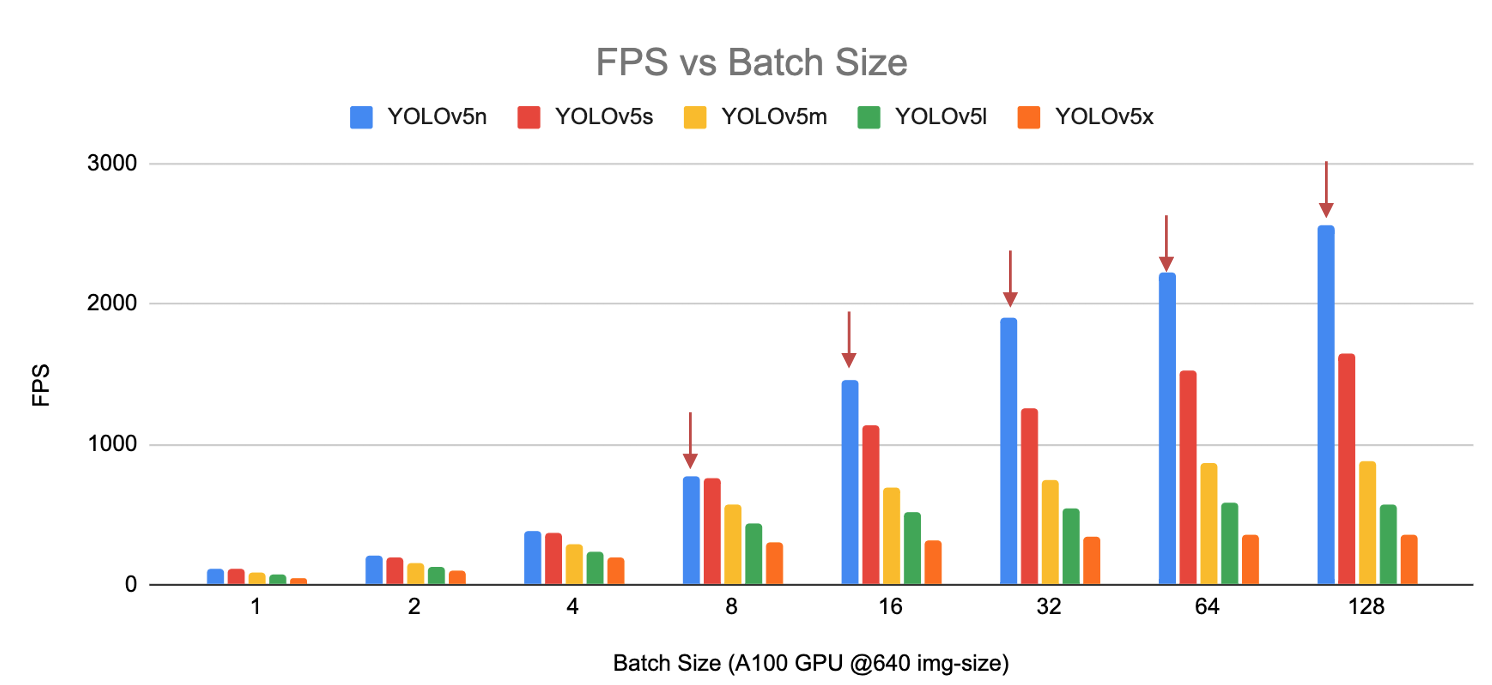
Ilość pamięci w kontekście głębokiego uczenia się, a zwłaszcza w treningu modeli sieci neuronowych, jest ściśle związana z pojęciem "batch size" (rozmiar paczki danych). Batch size określa liczbę przykładów treningowych używanych do aktualizacji wag modelu podczas jednej iteracji procesu treningowego. Zależy ona także od dostępnej ilości pamięci na urządzeniu używanym do treningu, czy to CPU czy GPU.
Odpowiedni dobór Batch Size ma wpływ na skuteczność treningu modelu oraz wydajność obliczeniową. Zbyt mała wartość może prowadzić do niestabilnego treningu, z kolei zbyt duża może przekroczyć dostępną pamięć i prowadzić do błędów. Istnieje zatem konieczność znalezienia optymalnej wartości w kontekście specyfiki modelu, dostępnego sprzętu oraz charakterystyki zbioru danych.
https://github.com/ultralytics/yolov5/discussions/6649
Przy wyborze ilości pamięci i batch size, istotne jest również uwzględnienie efektywności obliczeniowej. Dostępność odpowiedniej ilości pamięci wpływa na to, czy model może obsłużyć konkretne rozmiary paczek danych, co ma bezpośredni wpływ na tempo treningu. Optymalne dopasowanie ilości pamięci do wartości Batch Size pozwala na efektywne i stabilne trenowanie modelu, co jest kluczowe dla uzyskania wysokiej wydajności w zadaniach związanych z głębokim uczeniem się.
https://github.com/ultralytics/yolov5/discussions/6649
(tabelka z prezentacji z porównanie dla INT8/FP16/FP32 i różnych konfiguracji)
Podczas doboru odpowiedniej karty graficznej do zastosowań w dziedzinie Deep Learningu, kluczowym czynnikiem jest staranne rozważenie jej wydajności. Wysoka wydajność karty graficznej ma bezpośredni wpływ na tempo treningu i efektywność modeli sztucznej inteligencji. Zalety związane z wydajnością obejmują szybsze przetwarzanie danych, co umożliwia skrócenie czasu treningu modeli, szczególnie tych o większej złożoności.
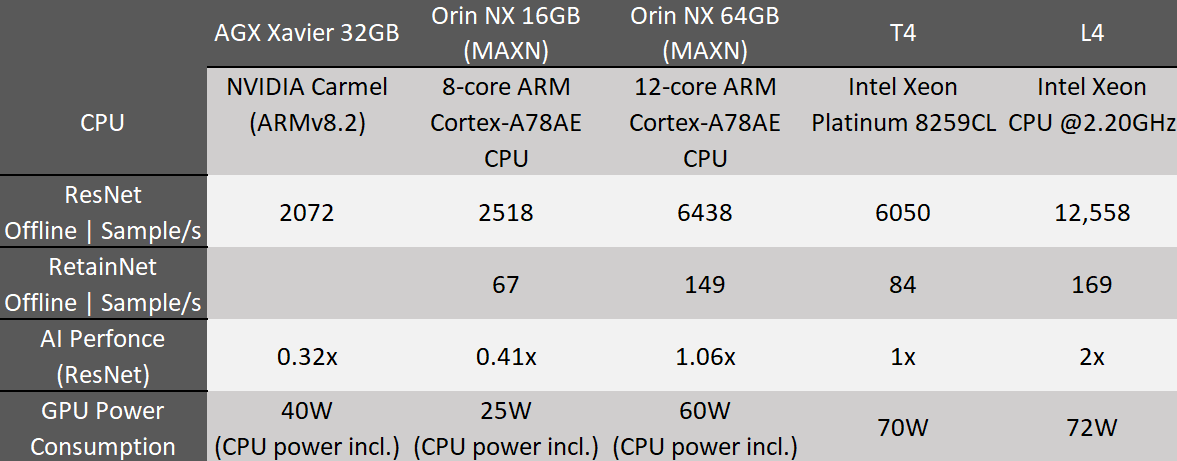
MLPerfedge inference
https://mlcommons.org/en/inference-edge-10/
https://mlcommons.org/en/inference-edge-30/
https://mlcommons.org/en/inference-edge-31/
Warto również zauważyć, że karty graficzne zaprojektowane z myślą o zastosowaniach Deep Learningu często posiadają specjalizowane jednostki obliczeniowe, takie jak tensorowe jednostki przetwarzania grafiki (TPU), co dodatkowo przyspiesza operacje związane z sieciami neuronowymi. Jednakże, zwiększona wydajność może wiązać się z wyższymi kosztami zakupu, co stanowi istotne rozważenie, szczególnie dla projektów o ograniczonym budżecie.
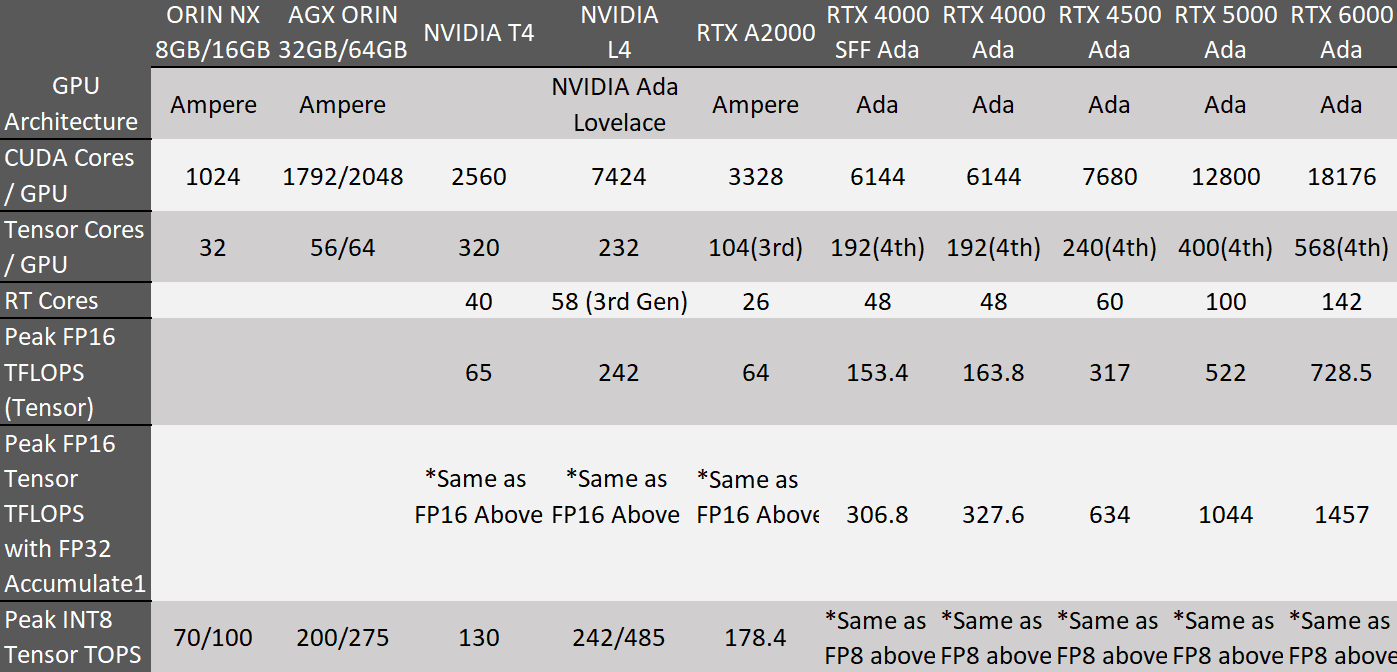
Z drugiej strony wysoka wydajność karty graficznej może generować większe zużycie energii, co prowadzi do zwiększonego ogrzewania się całego układu. Konieczne jest więc także zwrócenie uwagi na efektywność energetyczną, aby zminimalizować wpływ na koszty eksploatacji i środowisko. W rezultacie, zrównoważony dobór karty graficznej, uwzględniający zarówno jej wydajność, jak i koszty operacyjne, jest kluczowy dla osiągnięcia optymalnych rezultatów w projektach związanych z Deep Learningiem.

- Obsługa kart graficznych z serii NVIDIA® RTX do 130 W TDP
- Praca w szerokim zakresie temperatur od -25°C do 60°C
- Obsługa procesorów Intel® Alder Lake Core™ 12. generacji do 16C/24T 35W/65W
- 5x 2.5GbE i 1xGbE z opcjonalnym PoE+ (porty 3~6)
- 1x USB 3.2 Gen2x2 typ-C i 6x USB 3.2 typ-A
- Gniazdo M.2 2280 M key (Gen4x4) obsługujące dyski NVMe SSD
- Mieści dwa 2,5-calowe dyski twarde/SSD SATA z obsługą RAID 0/1
- Interfejs MezIO™ do rozbudowy o dodatkowe funkcje


Wybór karty graficznej dla profesjonalistów zajmujących się aplikacjami machine learning /deeplearning/AI to nie tylko kwestia wydajności. To szereg wielu parametrów, dotyczących m.in niezawodności, architektury, poboru prądu, a do tego dobrze byłoby to mieć w rozsądnej cenie.
Komputer Box PC do zastosowań AI, Intel Core i3/i5/i7/i9 12/13/14 gen., do 128GB RAM, możliwość montażu karty graficznej NVIDIA do 350W

Komputer Box PC do zastosowań AI, Intel Core i3/i5/i7/i9 12/13/14 gen., do 64GB RAM, możliwość montażu karty graficznej NVIDIA do 350W


























